Extracting Match Stats From Halo Infinite Film Files
Table of Contents
Introduction #
One of the conversations on my blog comments led to a discussion about film files in Halo Infinite. In case you are not familiar with them, no worries - it’s a pretty obscure component of the match data that I haven’t gone in-depth yet on my blog or here, on the OpenSpartan blog.
The idea behind film files is simple - they aren’t your traditional video but rather a combination of game engine metadata that is captured during your gameplay. When you complete a match, a “film” (a recording of all match metadata) is captured and you end up with a whole bunch of binary content that is available through a dedicated API endpoint.
Before we go down this rabbit hole, I want to give a massive shout-out to Andy Curtis for doing quite a bit of work digging through film file structure 🙌
Finding the film files #
Before we get to the film content, let’s figure out how we find them. To get started, first try to get your own matches from the Halo Infinite API. This will allow you get the match IDs that we can later use to query for film data. You can send a request to this endpoint to get the most recent matches:
https://halostats.svc.halowaypoint.com/hi/players/xuid({{XUID}})/matches?count=25
In the example above, {{XUID}} is the numeric identifier of your player ID. I talked about the process of converting a gamertag into a XUID in a separate blog post.
You will need to make sure that you authenticate for the API call above to succeed (and all other API calls in this blog post). You can learn more about this in Halo Infinite Web API Authentication.
The match data you will get will be by default in JSON format, like this:
{
"Start": 0,
"Count": 25,
"ResultCount": 25,
"Results": [
{
"MatchId": "4fb89c93-53e1-4d7e-b273-5f4c4c1a58e4",
"MatchInfo": {
"StartTime": "2024-09-16T02:35:15.505Z",
"EndTime": "2024-09-16T02:42:08.144Z",
"Duration": "PT6M31.0705518S",
"LifecycleMode": 3,
"GameVariantCategory": 9,
"LevelId": "1216247c-bf6d-4740-8270-e800a114f231",
"MapVariant": {
"AssetKind": 2,
"AssetId": "37a9b5f0-6be7-4a46-8010-1fe6f7ea5611",
"VersionId": "e1cbf812-4f4e-44fc-9ef8-dd9ab5c4e4cf"
},
"UgcGameVariant": {
"AssetKind": 6,
"AssetId": "0e198591-ac15-4f99-8ff2-dd390decad66",
"VersionId": "168e6c3a-fdf3-4edd-af79-c0ffe5475026"
},
"ClearanceId": "bb31018c-8ca3-4673-b870-5193cfdf18f5",
"Playlist": {
"AssetKind": 3,
"AssetId": "1b1691dc-d8b9-4b1f-825d-cb1c065184c1",
"VersionId": "38ecf0d8-82ca-4831-b186-eda51653f2ba"
},
"PlaylistExperience": 2,
"PlaylistMapModePair": {
"AssetKind": 7,
"AssetId": "6b7c20a9-5eed-476f-9716-6d20e2f37f1a",
"VersionId": "56c4ba81-a659-4168-bc02-8f4135e693f9"
},
"SeasonId": "Csr/Seasons/CsrSeason8-1.json",
"PlayableDuration": "PT6M31.063S",
"TeamsEnabled": true,
"TeamScoringEnabled": true,
"GameplayInteraction": 1
},
"LastTeamId": 1,
"Outcome": 2,
"Rank": 1,
"PresentAtEndOfMatch": true
},
[...MORE MATCH DATA...]
]
}
This is all useful metadata, but we are looking specifically for the match ID captured in the MatchId property. In my case, the match I am looking for is 4fb89c93-53e1-4d7e-b273-5f4c4c1a58e4, which is a recent Husky Raid game I’ve been a part of.
With the match ID in hand, we can now request the film chunks (every film has several “chunks” that are just binary data) by constructing the URL for another API endpoint, like this:
https://discovery-infiniteugc.svc.halowaypoint.com
/hi
/films
/matches
/4fb89c93-53e1-4d7e-b273-5f4c4c1a58e4
/spectate
If the call succeeds, the metadata you will get will look like this:
{
"FilmStatusBond": 1,
"CustomData": {
"FilmLength": 403190,
"Chunks": [
{
"Index": 0,
"ChunkStartTimeOffsetMilliseconds": 0,
"DurationMilliseconds": 11,
"ChunkSize": 465309,
"FileRelativePath": "/filmChunk0",
"ChunkType": 1
},
{
"Index": 1,
"ChunkStartTimeOffsetMilliseconds": 0,
"DurationMilliseconds": 19972,
"ChunkSize": 47858,
"FileRelativePath": "/filmChunk1",
"ChunkType": 2
},
{
"Index": 2,
"ChunkStartTimeOffsetMilliseconds": 19973,
"DurationMilliseconds": 20003,
"ChunkSize": 122480,
"FileRelativePath": "/filmChunk2",
"ChunkType": 2
},
[...MORE CHUNKS...]
],
"HasGameEnded": true,
"ManifestRefreshSeconds": 30,
"MatchId": "4fb89c93-53e1-4d7e-b273-5f4c4c1a58e4",
"FilmMajorVersion": 37
},
"BlobStoragePathPrefix": "https://blobs-infiniteugc.svc.halowaypoint.com/ugcstorage/film/1c7442bd-1f8d-4593-b7d0-1c95618c6876/e6796b9c-eb98-4c32-879a-5e5ab3d567f1/",
"AssetId": "1c7442bd-1f8d-4593-b7d0-1c95618c6876"
}
The way Halo Infinite API handles films is by splitting them up into separate chunks that contain different classes of in-game metadata during different parts of the game. You will see those chunks yourself when you are in theater mode - the timeline is clearly split into them (see the black markers):
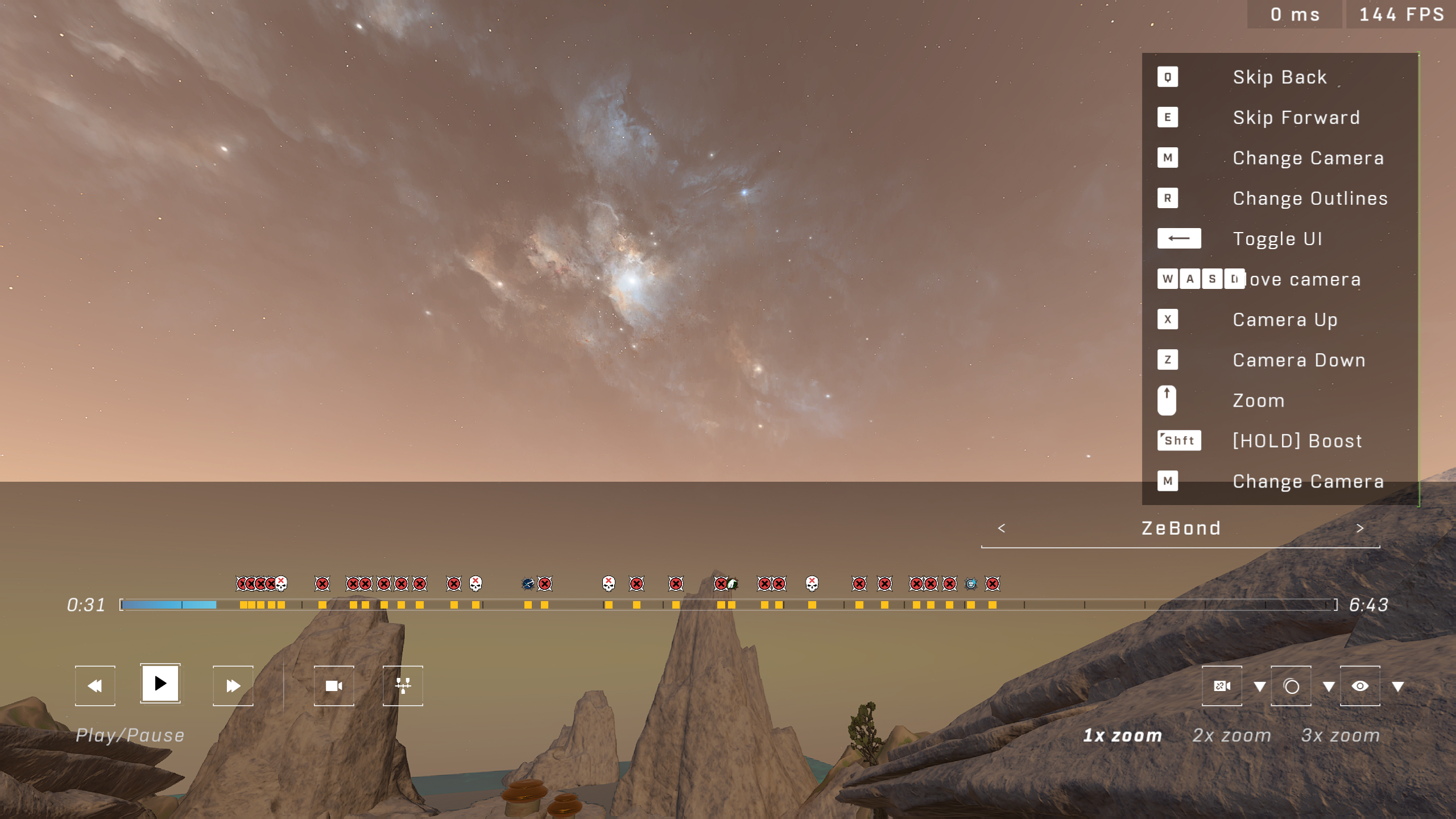
Film chunks are player-independent - they are recorded for the match itself and contain metadata about all players in them. To get the content of each chunk we will construct the URL based on the BlobStoragePathPrefix property and the FileRelativePath for each chunk:
https://blobs-infiniteugc.svc.halowaypoint.com
/ugcstorage
/film
/1c7442bd-1f8d-4593-b7d0-1c95618c6876
/e6796b9c-eb98-4c32-879a-5e5ab3d567f1
/filmChunk0
While this is not explicitly called out, the first GUID is the film asset ID and the second is the film asset version, similar to how game asset metadata is associated in the game CMS. If you have film IDs, you can get those directly without worrying about getting match IDs first.
With the URLs ready, we can now download every single chunk for a match and analyze them. If you are on Linux (or using Windows Subsystem for Linux) you can use this Bash script to quickly download all film chunks for a match (make sure to replace your token and clearance):
#!/bin/bash
# Check if match ID is provided
if [ "$#" -ne 1 ]; then
echo "Usage: $0 <MATCH_ID>"
exit 1
fi
MATCH_ID=$1
# Headers for the API request
AUTH_HEADER="x-343-authorization-spartan: v4=YOUR_TOKEN"
CLEARANCE_HEADER="343-clearance: CURRENT_CLEARANCE"
LANGUAGE_HEADER="Accept-Language: en-us"
ACCEPT_HEADER="accept: application/json"
echo "Fetching chunk information for match: ${MATCH_ID}..."
RESPONSE=$(curl --silent --location --request GET "https://discovery-infiniteugc.svc.halowaypoint.com/hi/films/matches/${MATCH_ID}/spectate" \
--header "${AUTH_HEADER}" \
--header "${CLEARANCE_HEADER}" \
--header "${LANGUAGE_HEADER}" \
--header "${ACCEPT_HEADER}" \
-w "%{http_code}" -o response.json)
HTTP_STATUS="${RESPONSE}"
echo $HTTP_STATUS
# Check for successful response
if [[ "$HTTP_STATUS" != "200" ]]; then
echo "Error fetching data: HTTP status $HTTP_STATUS"
exit 1
fi
# Extract the base URL and film chunk paths
BASE_URL=$(jq -r '.BlobStoragePathPrefix' response.json)
CHUNK_PATHS=$(jq -r '.CustomData.Chunks[].FileRelativePath' response.json | sed 's|^/||') # Remove leading slashes
# Clean up response file
rm response.json
# Loop through each chunk and download it
for CHUNK_PATH in $CHUNK_PATHS; do
# Construct the full URL
FULL_URL="${BASE_URL}${CHUNK_PATH}"
COMPRESSED_FILE="compressed${CHUNK_PATH##*/}"
DECOMPRESSED_FILE="DECOMPRESSED_${CHUNK_PATH##*/}"
# Download the compressed chunk
echo "Downloading chunk from ${FULL_URL}..."
curl --location --request GET "${FULL_URL}" \
--header "${AUTH_HEADER}" \
--header "${CLEARANCE_HEADER}" \
--header "${LANGUAGE_HEADER}" \
--header "${ACCEPT_HEADER}" \
--output "${COMPRESSED_FILE}"
# Decompress the chunk
echo "Decompressing ${COMPRESSED_FILE}..."
python3 -c "import zlib, sys; sys.stdout.buffer.write(zlib.decompress(sys.stdin.buffer.read()))" < "${COMPRESSED_FILE}" > "${DECOMPRESSED_FILE}.bin"
# Clean up compressed file
rm "${COMPRESSED_FILE}"
echo "Decompressed chunk saved as ${DECOMPRESSED_FILE}."
done
echo "All chunks downloaded and decompressed!"
You can make the script executable with chmod +x yourscript.sh and then run it by passing the match GUID as the first argument:
./yourscript.sh 1C5F57D3-1418-4BDE-A970-F8FAB6DFE110
This script helpfully decompresses the chunks as well, but we’ll get to that a bit later in this post.
As you look at the metadata for each chunk you will notice that individual chunks have a type. From what I can infer, they break down like this:
| Chunk type | Description |
|---|---|
1 |
Game bootstrap metadata |
2 |
In-game event captures |
3 |
Game summary metadata |
We’ll be using every single one of them in our explorations.
Dissecting chunk metadata #
Looking at existing chunks, we see that the ones that have the type of 1 or 2 have very sparse event data, at least on the surface. However, they contain valuable information that we will need. To explore the content, let’s download a random chunk for an existing match:
https://blobs-infiniteugc.svc.halowaypoint.com/ugcstorage
/film
/1c7442bd-1f8d-4593-b7d0-1c95618c6876
/e6796b9c-eb98-4c32-879a-5e5ab3d567f1
/filmChunk3
Opening it in a hex editor produces this result:
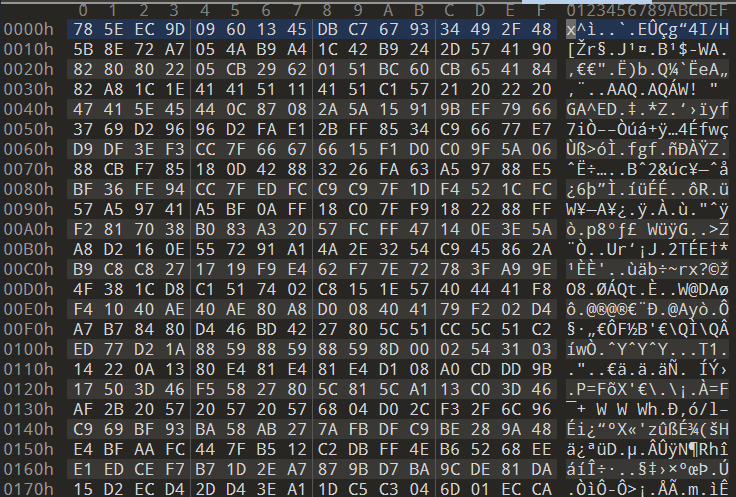
Not exactly “human-readable”, and that’s because we’re missing a core step here - decompression. The clue for that are the first two bytes of the chunk file 78 5E, which is an indicator of zlib Fast Compression. You can read more about it in the official RFC. Looks like we’re dealing with compressed data, and therefore need to make sure that we “extract” it before attempting to read the data.
Let’s do this a bit differently then - we’re going to download the binary file with cURL and then decompress it with Python. Assuming that you are not already using the script I shared earlier to download every chunk, our first step is this:
curl --location --request GET 'https://blobs-infiniteugc.svc.halowaypoint.com/ugcstorage/film/1c7442bd-1f8d-4593-b7d0-1c95618c6876/e6796b9c-eb98-4c32-879a-5e5ab3d567f1/filmChunk3' --header 'x-343-authorization-spartan: v4=YOUR_AUTH_HEADER' --header '343-clearance: YOUR_CLEARANCE' --header 'Accept-Language: en-us' --header 'accept: application/json' --output chunk-compressed.bin
And then, we can run a bit of inline Python magic to decompress the content we just downloaded into its own file - decompressed_output.bin:
python3 -c "import zlib, sys; sys.stdout.buffer.write(zlib.decompress(sys.stdin.buffer.read()))" < chunk-compressed.bin > decompressed_output.bin
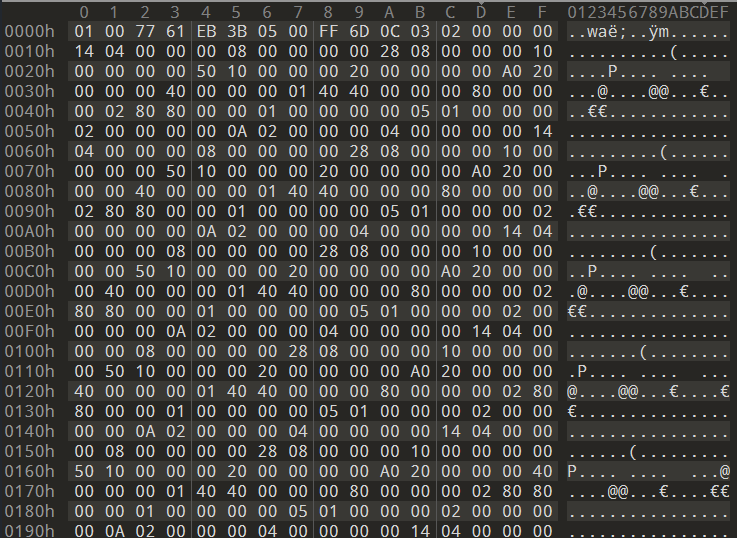
This looks a bit more promising because we actually see repeating patterns. It’s even more promising if we look up events inside the chunk by the XUID for a given player that existed in a match. Because I am using a hex editor, I can easily look up the UInt64 value (all XUIDs are unsigned 64-bit integers), leading me to this:
7:B1E0h 00 00 00 00 00 00 00 00 00 00 00 00 5A 00 65 00 ............Z.e.
7:B1F0h 42 00 6F 00 6E 00 64 00 00 00 00 00 00 00 00 00 B.o.n.d.........
7:B200h 00 00 00 00 00 00 00 00 00 00 00 00 00 E5 DE DE .............åÞÞ
7:B210h 03 00 00 09 00 2D C0 00 00 00 04 58 00 00 00 00 .....-À....X....
Because Halo Infinite is generally known to use quite a bit of Bond-encoded data, I wanted to pass the content of the file through my tool - bond-reader. Doing that was fruitless, though, as it turned out that the data is not Bond-formatted (at least not that I could tell from some short-term digging). I guess we’ll have to stick with proper inference of binary data based on vanilla binary pattern analysis.
Another wrench thrown into our plans was also detected by Andy Curtis the fact that data is not necessarily byte-aligned in the film chunks. That is - if you use a hex editor to spot all existing patterns you might find some but there is quite a bit of data “hiding” in plain sight because it just isn’t properly positioned for a hex editor to render it.
Decoding unaligned data #
Because we can’t count on just our hex editor to find the data, we can write some custom code to find the things we want that are not aligned with our expectations 😎
To do that, here is a complete C# application that does just that - if you give it a byte pattern to search for (disregard the actual example pattern - it’s just a demo), it will try to find it regardless of how the data is actually aligned in the file:
namespace ComponentSearchByteAlign
{
internal class Program
{
public static void Main(string[] args)
{
byte[] data = File.ReadAllBytes(@"PATH_TO_YOUR_DECOMPRESSED_BIN_FILE");
// This can be a XUID or a gamertag to easily spot the data sequences
byte[] pattern = { 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF };
List<int> matchPositions = FindPattern(data, pattern);
if (matchPositions.Count > 0)
{
Console.WriteLine($"Pattern found at bit positions ({matchPositions.Count} total):");
foreach (int position in matchPositions)
{
Console.WriteLine(position);
}
}
else
{
Console.WriteLine("Pattern not found.");
}
}
public static List<int> FindPattern(byte[] data, byte[] pattern)
{
List<int> matchPositions = [];
int dataBitLength = data.Length * 8;
int patternBitLength = pattern.Length * 8;
for (int bitPos = 0; bitPos <= dataBitLength - patternBitLength; bitPos++)
{
if (IsBitMatch(data, pattern, bitPos))
{
matchPositions.Add(bitPos);
}
}
return matchPositions;
}
public static bool IsBitMatch(byte[] data, byte[] pattern, int bitOffset)
{
// Calculates the number of whole bytes to skip.
// We divide bitOffset by 8 because there are 8 bits per byte.
int byteOffset = bitOffset / 8;
// Calculates how far into the byte (number of bits) we need to start.
// It's the remainder when bitOffset is divided by 8, giving the bit position within the byte.
int bitShift = bitOffset % 8;
// On the above, a good example to visualize the behavior:
// If bitOffset = 10, byteOffset = 1 (skip 1 full byte) and bitShift = 2 (start at the 3rd bit in the second byte - we skip 2).
// We now iterate through every byte in the pattern that is given to
// us when the function is called.
for (int i = 0; i < pattern.Length; i++)
{
// Get the data byte that alligns with the current
// pattern byte and shifts the bits to the left by the
// calculated bit shift value earlier.
byte dataByte = (byte)(data[byteOffset + i] << bitShift);
// If bitShift > 0, include bits from the next byte. This is
// important for scenarios where, for example, we're shifting
// by 3 bits, meaning that part of the data will come from the
// next byte.
if (byteOffset + i + 1 < data.Length && bitShift > 0)
{
// Shifts the next byte to the right by the delta between 8
// and the calcualted bit shift value, aligning it with the
// remaining part of the data byte.
// Note: bitwise OR (|=) is used to combine the shifted parts
// so that we can perform a full byte comparison.
dataByte |= (byte)(data[byteOffset + i + 1] >> (8 - bitShift));
}
// Compare dataByte with the current byte in the pattern
if (dataByte != pattern[i])
{
// Not matching at position. No point in
// continuing.
return false;
}
}
// All bits match
return true;
}
}
}
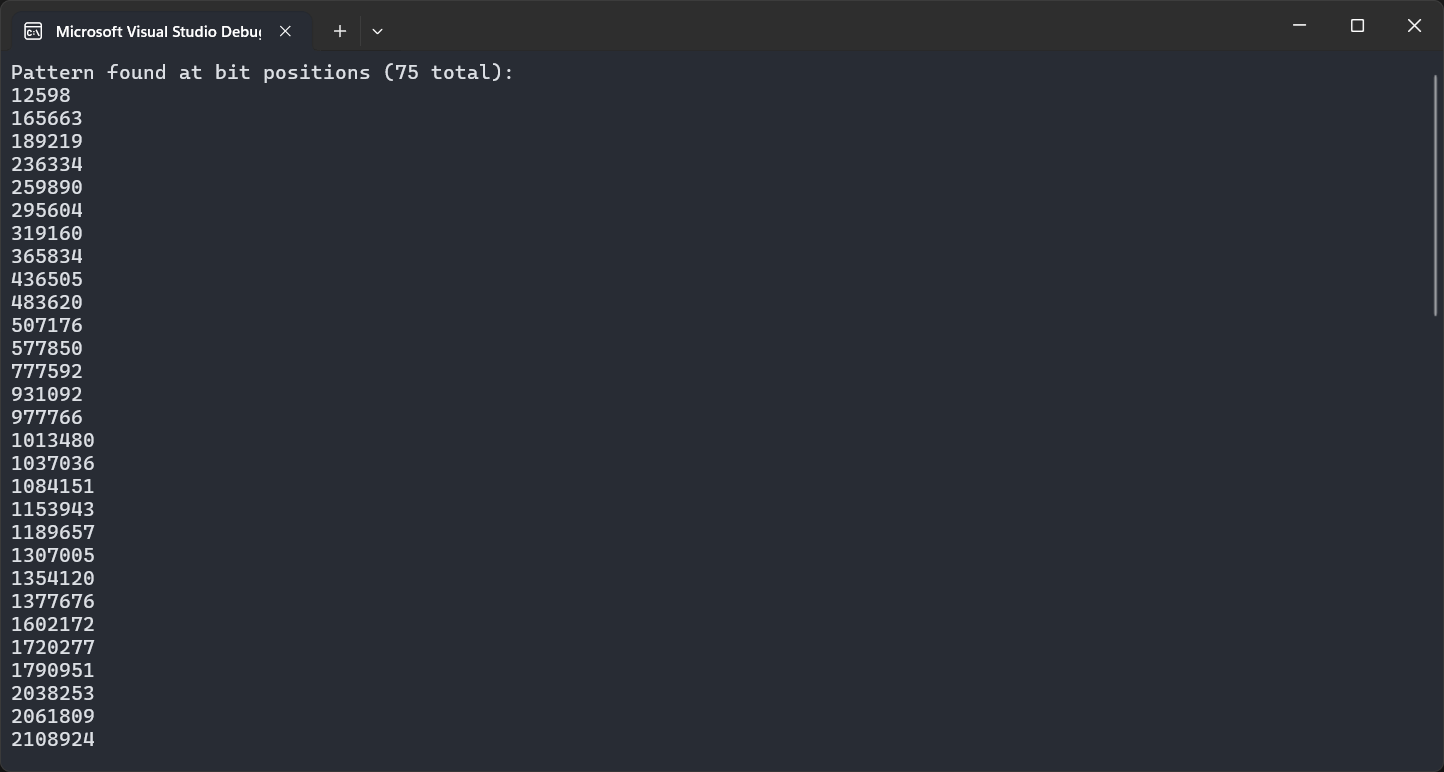
Running this code will enable us to quickly detect the positions of data sequences that contain relevant information. For example, one of the observations about the film file is that we can spot XUID references by looking at the 0x2D 0xC0 pattern. If we use this pattern and run the tool across a set of film chunks we’ll see quite a few results:
How bit shifting works #
Before we go any further, though, let me explain a bit the “magic” of bit shifting that you might’ve noticed in the program above. Let’s say we have a data array like this:
| Byte Index | Hex Value | Binary |
|---|---|---|
| 0 | 0xAB |
10101011 |
| 1 | 0xCD |
11001101 |
| 2 | 0xEF |
11101111 |
| 3 | 0x12 |
00010010 |
The pattern we want to look for is this:
| Byte Index | Hex Value | Binary |
|---|---|---|
| 0 | 0xCD |
11001101 |
| 1 | 0xEF |
11101111 |
Let’s pick a random bit offset - 10. that means that we’re starting at the 10th bit in the data array. If we look at the IsBitMatch function, it takes the bit offset as an argument.
That means that if we pass 10 as the value, we get a byteOffset of 1, meaning that we skip an entire byte (just one) when looking for the data.
Now, keep in mind that when calculating byteOffset it was not a “clean” division - we have a remainder, that is helpfully captured by bitShift, and that remainder is equal to 2, which means that with the byte at index 1 (remember, we skipped the one at 0), we start with the third bit (skip first two, as bitShift tells us).
That can be visualized in a table like this:
| Byte Index | Hex Value | Binary | Comment |
|---|---|---|---|
| 0 | 0xAB |
10101011 |
We’re skipping this entirely. |
| 1 | 0xCD |
11001101 |
We start comparing from the third bit. |
| 2 | 0xEF |
11101111 |
We’ll use the data from this bit to make sure we can build a full byte. |
| 3 | 0x12 |
00010010 |
Used in comparison later. |
Now, I mentioned that we start our parsing with the byte at index 1 at the third bit. Look at the binary representation for that byte:
11001101
We skip the first two bits, and shift the bits left, padding the “missing” bits with zeroes at the end:
00110100
Now, instead of using the zeroes, we can steal the two leading bits from the next byte in our sequence (at index 2 - that is, 0xEF). We shift it right by six bits to the right to get the top 2 bits (because that’s all we need to complete it), so that:
11101111
Becomes:
00000011
So now from the shifted bytes we have these two values:
00110100
00000011
Combining them gives us:
00110111
This binary value does not match the first value of our pattern (11001101), so the search will move on from the next offset, and so on.
Digging through the chunks #
So now that we have an idea on how to look for data we can start looking at individual “envelopes” that contain player details. As I mentioned above, there are many chunks that are usually provided for a given film; however, the ones that capture specific events, like deaths, kills, or medal awards, are all aggregated in the last film chunk file, with the ChunkType of 3.
Within the very last chunk (of type 3) the events are usually structured like this:
| Header | Gamertag (Unicode) | Padding | Type | Timestamp | Padding | Medal Marker | Padding | Metadata (Medal Type) |
|---|---|---|---|---|---|---|---|---|
| 12 bytes | 32 bytes | 15 bytes | 1 byte | 4 bytes | 3 bytes | 1 byte | 3 bytes | 1 byte |
Be careful with assuming that a gamertag is unique within a match. There were cases where the same match had a gamertag like MyGamertag and another MsMyGamertag - you can’t search just for MyGamertag as that will produce some unexpected results. You need to check that there are 12 preceding bytes of “header” (arbitrary given that I don’t know what they represent, but consistent for individual gamertags) exist and then the headers before that are 0x00 (I limit to 3 zero bytes). That way you can ensure that you are extracting a properly offset event.
Some matches may not have a chunk of type 3 - that’s very likely a bug in the API. Without this chunk there is no timeline you can parse as easily. Additionally, it’s entirely possible that the chunk of type 3 doesn’t contain gamertag-associated data. Additional investigation is needed to understand that behavior.
If you are using a tool like 010 Editor and extract the binary data on a per-file basis (i.e., find the bit positions for the gamertag start and then extract the bytes into its own file from there), you can use the following extremely basic binary template to highlight the sequences for easier parsing:
struct HEADER
{
char bytes[12];
};
struct GAMERTAG
{
char bytes[32];
};
struct TYPE
{
char bytes[1];
};
struct TIMESTAMP
{
char bytes[4];
};
struct BUFF_PADDING
{
char bytes[15];
};
struct PADDING
{
char bytes[3];
};
struct MEDAL_MARKER
{
char bytes[1];
};
local int offset = 0;
HEADER header <bgcolor=0x659157>;
offset += sizeof(HEADER);
FSeek(offset);
GAMERTAG gt <bgcolor=cGreen>;
offset += sizeof(GAMERTAG);
FSeek(offset);
BUFF_PADDING bp <bgcolor=cBlue>;
offset += sizeof(BUFF_PADDING);
FSeek(offset);
TYPE type <bgcolor=cYellow>;
offset += sizeof(TYPE);
FSeek(offset);
TIMESTAMP ts <bgcolor=cRed>;
offset += sizeof(TIMESTAMP);
FSeek(offset);
PADDING padding <bgcolor=cBlue>;
offset += sizeof(PADDING);
FSeek(offset);
MEDAL_MARKER mm <bgcolor=0xF7AF9D>;
offset += sizeof(MEDAL_MARKER);
FSeek(offset);
PADDING padding <bgcolor=cBlue>;
offset += sizeof(PADDING);
FSeek(offset);
MEDAL_MARKER mtype <bgcolor=0xFFC0CB>;
offset += sizeof(MEDAL_MARKER);
FSeek(offset);
The structure above is consistent across matches - I’ve extracted thousands of my own games and ran into minimal issues (with the exception of a few stray gamertags).
Extracting timeline metadata #
Out of all the fields above, the most interesting to me is the metadata one. The metadata field (i.e., the medal type) is capturing numeric values that represent medals. The values are different from the medal mapping. There is no clear mapping between those and a human-readable JSON representation, so we need to infer them by looking at medal volume here and correlate with medals earned per match or through a player’s career. Andy Curtis did the heavy lifting on this for some medals in his SPNKr project (a few are pending additional research).
The following medals are currently known:
| Medal ID | Medal |
|---|---|
| 0 | Double Kill |
| 1 | Triple Kill |
| 2 | Overkill |
| 3 | Killtacular |
| 4 | Killtrocity |
| 5 | Killamanjaro |
| 6 | Killtastrophe |
| 7 | Killpocalypse |
| 8 | Killionaire |
| 9 | Killing Spree |
| 10 | Killing Frenzy |
| 11 | Running Riot |
| 12 | Rampage |
| 13 | Perfection |
| 26 | Killjoy |
| 27 | Nightmare |
| 28 | Boogeyman |
| 29 | Grim Reaper |
| 30 | Demon |
| 31 | Flawless Victory |
| 32 | Steaktacular |
| 36 | Stopped Short |
| 37 | Flag Joust |
| 38 | Goal Line Stand |
| 39 | Necromancer |
| 43 | Ace |
| 44 | Extermination |
| 45 | Sole Survivor |
| 46 | Untainted |
| 47 | Blight |
| 48 | Disease |
| 49 | Plague |
| 51 | Pestilence |
| 53 | Culling |
| 54 | Cleansing |
| 55 | Purge |
| 56 | Purification |
| 57 | Divine Intervention |
| 58 | Zombie Slayer |
| 59 | Undead Hunter |
| 60 | Hell’s Janitor |
| 61 | The Sickness |
| 62 | Spotter |
| 63 | Treasure Hunter |
| 64 | Saboteur |
| 65 | Wingman |
| 66 | Wheelman |
| 67 | Gunner |
| 68 | Driver |
| 69 | Pilot |
| 70 | Tanker |
| 71 | Rifleman |
| 72 | Bomber |
| 73 | Grenadier |
| 74 | Boxer |
| 75 | Warrior |
| 76 | Gunslinger |
| 77 | Scattergunner |
| 78 | Sharpshooter |
| 79 | Marksman |
| 80 | Heavy |
| 81 | Bodyguard |
| 82 | Back Smack |
| 83 | Nuclear Football |
| 84 | Boom Block |
| 85 | Bulltrue |
| 86 | Cluster Luck |
| 87 | Dogfight |
| 88 | Harpoon |
| 89 | Mind the Gap |
| 90 | Ninja |
| 91 | Odin’s Raven |
| 92 | Pancake |
| 93 | Quigley |
| 94 | Remote Detonation |
| 95 | Return to Sender |
| 96 | Rideshare |
| 97 | Skyjack |
| 98 | Stick |
| 99 | Tag & Bag |
| 100 | Whiplash |
| 101 | Kong |
| 102 | Autopilot Engaged |
| 103 | Sneak King |
| 104 | Windshield Wiper |
| 105 | Reversal |
| 106 | Hail Mary |
| 107 | Nade Shot |
| 108 | Snipe |
| 109 | Perfect |
| 110 | Bank Shot |
| 111 | Fire & Forget |
| 112 | Ballista |
| 113 | Pull |
| 114 | No Scope |
| 115 | Achilles Spine |
| 116 | Grand Slam |
| 117 | Guardian Angel |
| 118 | Interlinked |
| 119 | Death Race |
| 120 | Chain Reaction |
| 121 | 360 |
| 122 | Combat Evolved |
| 123 | Deadly Catch |
| 124 | Driveby |
| 125 | Fastball |
| 126 | Flyin’ High |
| 127 | From the Grave |
| 128 | From the Void |
| 129 | Grapple-jack |
| 130 | Hold This |
| 131 | Last Shot |
| 132 | Lawnmower |
| 133 | Mount Up |
| 134 | Off the Rack |
| 135 | Quick Draw |
| 137 | Pineapple Express |
| 138 | Ramming Speed |
| 139 | Reclaimer |
| 140 | Shot Caller |
| 141 | Yard Sale |
| 142 | Special Delivery |
| 146 | Fumble |
| 148 | Straight Balling |
| 151 | Always Rotating |
| 152 | Hill Guardian |
| 153 | Clock Stop |
| 154 | Secure Line |
| 156 | Splatter |
| 162 | All That Juice |
| 163 | Great Journey |
| 165 | Breacher |
| 166 | Mounted & Loaded |
| 167 | Monopoly |
| 168 | Counter-snipe |
| 174 | Driving Spree |
| 175 | Death Cabbie |
| 176 | Immortal Chauffeur |
| 177 | Blind Fire |
| 178 | Hang Up |
| 179 | Call Blocked |
| 180 | Clear Reception |
The event type, also captured in the envelope, can be one of the following:
| Type (Decimal) | Description |
|---|---|
10 |
Mode-specific events (e.g., captured the flag, killed the carrier, stole the flag) |
20 |
Death |
50 |
Kill |
Any other type identifier (such as 51, 100, or 250) that you may see here, when associated with a medal, is representative of the medal sorting weight. It maps 1:1 to the information that you can get from the medal metadata endpoint.
Timestamp data is represented in milliseconds from the start of the match. You can obtain a readable value with a C# snippet like this:
Array.Reverse(timestampBytes);
var timestamp = BitConverter.ToUInt32(timestampBytes, 0);
One thing that I haven’t yet figured out is how assists are tracked within the event batch. It’s likely captured as a XUID reference further in the event envelope that I didn’t get to. This will be a topic for another blog post in the future as we dig more through the film file format.
Finding the gamertags #
Notice that to extract all events from the last chunk one specific thing is still needed - we need to start with knowing the gamertags for which the events should be extracted. And because gamertags are technically arbitrary text, we need to find an index somewhere. To do that, we can look inside all other chunks (other than ones of type 3). That’s right, for us to get the list of gamertags that were involved in a given game we need to download and parse all existing film chunks other than the very last one that has ChunkType set to 3.
The last chunk contains information on all players in the game but doesn’t seem to contain a very clear XUID and Gamertag combination that will allow us to extract them cleanly. Luckily, inside all other chunks (where ChunkType is either 1 or 2), the gamertags and XUIDs can be found by looking at the pattern: 0x2D 0xC0. From that pattern, we can deduce the following structure:
| Gamertag (Unicode) | Padding | XUID | Marker 1 | Marker 2 |
|---|---|---|---|---|
| Dynamic length (32 bytes max) | 21 bytes | 8 bytes | 0x2D |
0xC0 |
Keep in mind that gamertags are stored as Unicode (UTF-16) text. This means that the padding can be deceiving if you are looking at the binary file - you might think that there are 22 0x00 bytes before the gamertag value, when in fact the last zero byte is just the trailing byte for the gamertag text. Make sure to be careful when parsing the values.
We can scan all film chunks for this pattern by identifying the markers, getting the XUID, checking that the preceding 21 bytes are 0x00 (padding zero bytes), and then grab 32 bytes of the gamertag data that can be parsed as a Unicode string. There are more safeguards we can put in place for this logic, but ultimately it’s good enough to extract the basic data.
Once the data is extracted into, say, a dictionary, we can use that as a starting point to look up gamertags in the final (summary) chunk.
As I mentioned earlier, depending on the matches that you are getting, some of them might not have a chunk with ChunkType equal to 3. Others can return HTTP 404 (blob does not exist) errors when attempting to download a chunk. The former may be a bug. The latter is likely caused by the folks at 343 occasionally cleaning up the storage from older matches.
In C#, the extraction logic can be formalized as such:
public static byte[] ExtractBitsFromPosition(byte[] data, int startBitPosition, int bitLength)
{
// Calculate the actual end bit position
int endBitPosition = startBitPosition + bitLength - 1;
// Validate input parameters
if (startBitPosition < 0 || endBitPosition < 0 || startBitPosition >= data.Length * 8 || endBitPosition >= data.Length * 8 || startBitPosition > endBitPosition)
{
throw new ArgumentOutOfRangeException("Bit positions are out of range or invalid.");
}
// Calculate the byte offset and bit shift for the start position
int startByteOffset = startBitPosition / 8;
int startBitShift = startBitPosition % 8;
// Calculate the byte offset and bit shift for the end position
int endByteOffset = endBitPosition / 8;
int endBitShift = endBitPosition % 8;
// Calculate the number of bytes to extract
int byteCount = endByteOffset - startByteOffset + 1;
// If there's no bit shift, we can return from the byte offset onward
if (startBitShift == 0 && endBitShift == 0)
{
byte[] result = new byte[byteCount];
Array.Copy(data, startByteOffset, result, 0, byteCount);
return result;
}
// Otherwise, we need to shift the bits manually
byte[] extractedData = new byte[byteCount];
// Go byte by byte, shift and copy
for (int i = 0; i < byteCount - 1; i++)
{
// Shift the current byte and take bits from the next byte if needed
extractedData[i] = (byte)((data[startByteOffset + i] << startBitShift) | (data[startByteOffset + i + 1] >> (8 - startBitShift)));
}
// Handle the last byte (since it has no next byte to pull from)
extractedData[byteCount - 1] = (byte)(data[startByteOffset + byteCount - 1] << startBitShift);
// Mask the last byte to only include bits up to endBitShift
extractedData[byteCount - 1] &= (byte)(0xFF >> (7 - endBitShift));
return extractedData;
}
Recall that the data may or may not be byte-aligned so we need to operate on individual bits. In turn, once we find the marker pattern in film segment chunks (as we try to spot the gamertag and XUID combos), we can extract it with a function like this (where pattern is set to 0x2D 0xC0):
public static void ProcessData(byte[] data, byte[] pattern)
{
List<int> patternPositions = FindPattern(data, pattern);
foreach (int patternPosition in patternPositions)
{
int xuidStartPosition = patternPosition - 8 * 8;
byte[] xuid = ExtractBitsFromPosition(data, xuidStartPosition, 8*8);
var convertedXuid = ConvertBytesToInt64(xuid);
if (convertedXuid != 0)
{
int prePatternPosition = xuidStartPosition - 21 * 8;
var bytePrefixValidated = AreAllBytesZero(data, prePatternPosition, 21 * 8);
if (bytePrefixValidated)
{
Console.WriteLine($"XUID: {convertedXuid}");
byte[] undefinedData = ExtractBitsFromPosition(data, prePatternPosition - 32 * 8, 32 * 8);
Console.WriteLine($"Undefined Data (until 0x00 0x00): {ConvertBytesToText(undefinedData)}");
}
}
}
Console.ReadLine();
}
To simplify how I extract the data, I built a tool called OpenSpartan/film-event-extractor which will let you log in with your Xbox Live ID and aggregate all match data within a local SQLite database. The entire parsing logic is very much in flux (feel free to follow the discussion on this), but once it stabilizes I can see integrating this better in OpenSpartan Workshop.
For my own account, having played more than seven thousand matches, the entire aggregation took around 48 hours. I haven’t yet optimized (and parallelized) the code, so this can be attributed to also me building a slower-than-needed tool, but it works for now and I can start analyzing the data.
The data that is available through the API is mostly good as-is, but an expanded dataset that accounts for film-based details enables me to see two things more clearly:
- Mapping between gamertags and XUIDs at the time of the match (gamertags are mutable as users can change them, XUIDs are immutable). This way I don’t need to worry about doing out-of-band conversion to get an understanding of who I played against, since the match details API only returns XUIDs.
- Times when specific events occur in-game. I can see how quickly I earn the first medal in the game, or how quickly I get to the first kill or death.
What’s next #
There are are a few improvements that I want to make to both the open-source tool that I built as well as to my understanding of the film files. I alluded to assists earlier - that’s a data point that I definitely want to cover. Additionally, film files may contain the data required for us to build heatmaps of map movement. For that, we need to better try and replicate behaviors in the game - that is, understand how binary data changes with movement, weapon switches, use of grenades, and so on. Something tells me it will be a much more protracted project than I initially anticipated 🤔